摘 要
单株脱粒机是农作物科研育种工作重要环节,机械脱粒可以提高工作效率,减少科研劳动强度,节约人工成本。目前很多作物已经发明了专用的单株脱粒机,例如小麦、水稻、玉米等。而农作物单株脱粒研制在我国还是空白,多数科研单位主要还是靠人工捶打或者手工剥荚进行单株脱粒。国外已经发明了农作物单株脱粒机,但是进口农作物单株脱粒机价格昂贵,维修需要专门的进口配件,零部件转运周期长,且存在各种不足之处。近年来,国内通过借鉴和改造,设计出的农作物单株脱粒机,或多或少存在清机不彻底、易混杂和破碎率高等问题。单株脱粒要求机械脱粒要速度快,损失小,籽粒完好无损伤;清选是把杂质去除,留下干净籽粒,最重要是机器内不能有籽粒夹杂现象。本设计的单株脱粒机具有操作安全可靠、效率高、不混杂、损失少、脱粒干净、清洁度高等优点。
关键词:单株;农作物;脱粒机;脱粒;设计
Abstract
Plot yield soybean thresher is important link in soybean research and breeding work, mechanical threshing can improve work efficiency and reduce the scientific labor intensity, saving labor costs. At present many crops have invented a special individual thresher, such as wheat, rice, corn, etc. And soybean plant threshing research is still blank in our country, most of the research unit is still mainly rely on artificial beat or manual peel pods per plant threshing. Abroad have invented the soybean single plant threshing, but imported soybean plant thresher is expensive, maintenance need special imported components and parts transfer cycle is long, and there are many shortcomings. In recent years, domestic by reference and renovation, design of soybean plant thresher, more or less exist cleaning machine, easy to mix with incomplete and broken rate is high. Plant threshing requirements to speed, mechanical threshing losses small, grain in good condition without damage; Cleaning is to remove impurities, leaving a clean the grain, the heaviest if the machine is the grain mixed phenomenon. This design of residential area of soybean thresher is safe and reliable operation, high efficiency, not mixed, less damage, threshing clean, high cleanliness, etc.
Keywords: Per plant; Soybean; Threshing Machine; Design
II
目 录
摘 要 I
Abstract II
1 绪 论 1
1.1 设计的目的与意义 1
1.2 国内外发展现状 1
1.2.1 国外发展现状 1
1.2.2 国内发展现状 2
2脱粒机的总体方案选择分析及工作原理 3
2.1 总体方案的选择 3
2.2 总体结构 3
2.3 工作原理 4
3 电动机的选择 5
3.1 电动机类型和结构 5
3.2 选择电动机的容量 5
3.3 选择电动机的型号 5
4 带传动的设计 7
4.1 确定计算功率Pc 7
4.2 确定V带型号 7
4.3 确定传动比i 7
4.4 计算带轮直径 7
4.5 验算带速V 7
4.6 校核小带轮的包角α1 8
4.7 计算所需V带根数Z 8
5 螺旋输送器(搅龙)的设计 9
5.1 搅龙的结构型式 9
5.2搅龙叶片的螺旋角 9
5.3 搅龙的内径D1 10
5.4搅龙的外径D2 10
5.5搅龙的螺距S 10
5.6搅龙的转速n 10
5.7计算搅龙带轮直径 10
6 机架的设计 11
6.1 断面形状和尺寸选择 11
6.2 结构设计 11
7 主轴的设计和校核 12
7.1 选择轴的材料 12
7.2 确定轴的直径 12
7.3 轴的结构设计 13
7.4 轴上零件的周向定位 13
7.5 滚筒主轴的强度校核 13
7.6 键连接的强度校核 15
8 轴承的选用 17
9 总 结 18
参考文献 19
致 谢 20
1 绪 论
1.1 设计的目的与意义
随着我国农业的快速发展,我国越来越关注农村问题,农业机械化的发展速度进一步加大,由机械代替人力作业已是我国农业发展的一个趋势,而要实现我国农业的的现代化,其物质承担者农业机具的开发与利用必须紧跟上;同时为了完成和巩固本科知识和课程的学习;因此也就有了此时这篇设施作业机具全喂入式单株脱粒机的设计。
我国是一个以农业生产为主的发展中国家,农业的兴衰与人们的生活,甚至国家的稳定息息相关。但是现在随着人口的增加和环境恶化,我国农业发展也面临着严峻考验。如何让在日常的生产影响中有效地提高生产率,实现一机多用是摆在人们面前的一个棘手的问题。实现农业的现代化、智能化是今后农业的必然选择。
通过采用现代农业工程和机械技术,为生产提供更多有利条件,并在某种程度上,有效地摆脱了对自然环境和农业生产的依赖。它在人们的生活需求日益增长的同时发展起来,农业生产是在人工可控制条件下,具有高投资、高技术含量、高质量等特点。
近期生产收获作业机具发展重点是:开发全喂入式单株脱粒机,合理选择配套动力。体积和质量小、动力足,操作舒适,减轻劳动强度是必然要求,动力最好选用电动机。
南方地区为了解决晚稻的肥料的问题,夏收的时侯有稻草回田当绿肥用的习惯,这一点,全喂入单株脱粒机解决的比较好,当在田间作业时,因脱粒后全部茎秆都被打碎了,有助于梨耕,茎秆也易于腐烂。可见自古至今,脱粒生产对于农业生产的重要性,因此在现阶段对设施作业机具机构的研究和设计是很有必要的。同时,脱粒机发展趋势也成为各界关注的焦点。在这种情况下,有必要对我们国家的脱粒机发展现状和未来发展趋势等问题认真研究,形成正确认识,不仅对当前我国轴流式脱粒相关行业技术进步和产品定位具有重要意义,并对行业的未来发展有好处。
1.2 国内外发展现状
1.2.1 国外发展现状
国外单株脱粒机的发展,基本上分为欧美和日本两大类型。所谓欧美型,也就是说这些国家以旱地为主,地块大,各类作物以小麦为主。而日本型是指以水田为主,大块小,经常规模也小,以水稻为主。因此,前者用的脱粒机是大型的,大功率的,而后者用的机型都是小型的或中型的。
虽然上述两类地区因其自然条件不同,使用的机型不同,但其实现粒物收获过程机械化所经历的过程却大体上是相同的,即都是先从半机械化开始,然后逐步向机械化过渡,最后实现收获过程机械化。到了五十年代,已基本上实现了收获过程的半机械化。例如美国在1950年已拥有70万左右的脱粒机,这时的机收面积已占收获面积的75%。基本上实现了半机械化,到 了七十年代初美国脱粒机的数量达到85万之多。机收面积达到了95%以上。正向大型、高效及自动化发展。
日本的情况有所不同,实现收获过程半机械化的进程要比欧美国家慢得多,当然这里面有些客观原因,地块小,且是水田作业,因此到了六十年代的中期开始探索适用于日本的脱粒机。到了七十年代中期大约前后用了十年左右的时间,研制出多种适用于日本的脱粒机,脱粒机等产品。目前已大量推广使用,可以说已基本上实现了收获的过程半机械化。
从研究的动向看,着重于以下几方面的研究:一是机具的可靠性;二是改善操作性能,提高自动化程度;三是使脱粒机更能适应作物生长的自然条件,以提高脱粒机的适应性、效率和工作质量。四是提高劳动生产率。
1.2.2 国内发展现状
解放前,单株脱粒机也和其它农业机械一样是个空白,根本谈不上研制。解放后,农业机械化发展很快,单株脱粒机有了很大的发展,华北和东北不少地区已开始使用我国自己生产的脱粒机。近几年我国已先后研制出几种适用于北方地区使用的新机型,并已定型大批投产。我国南方十三个省市、区、市近年来大力发展了对脱粒机的研制,取得重大突破。机型都为全喂入式的,脱粒后不能保持茎秆完整,为了解决广大农民这一迫切要求,我国南方地区从1970年开始研制半喂入式脱粒机。经过短短几年努力,取得了重大成果,到目前为止先后经省、区、市级定型的样机已有十五种,形式多种多样,有大有小。这些机型目前正大批投产,早定型投产的样机,目前已在农业生产上发挥了作用。
事物总是不断发展的,单株脱粒机的研制工作也是一样,还需要不断的提高和发展;比如研究更为合理的新机型,实现标准化、系列化,并把新技术、新工艺和新材料应用到脱粒机上,以便提高脱粒机的工作可靠性,改善其操作性能,减轻机器重量,提高其耐用度和降低造价。
2脱粒机的总体方案选择分析及工作原理
2.1 总体方案的选择
单株脱粒机采用的是全喂入型脱粒机构,对于半喂入型脱粒机构,其对作物的自然状况比较敏感,生长乱的作物及高矮参差达的作物脱粒时,可能会造成无法脱净。
单株脱粒机适于脱粒清选稻、麦及豆类、油菜、高粱、小米等多种农作物的全喂入式单株脱粒机,属于一种农机设备。
总体方案确定的依据:1)完成农作物的脱粒,保证脱尽率99%以上;2)要求农作物破碎损失率不得大于0.5%;3)要求生产率高,机构简单,易维修,工作可靠;4)杂物尽量少;
2.2 总体结构
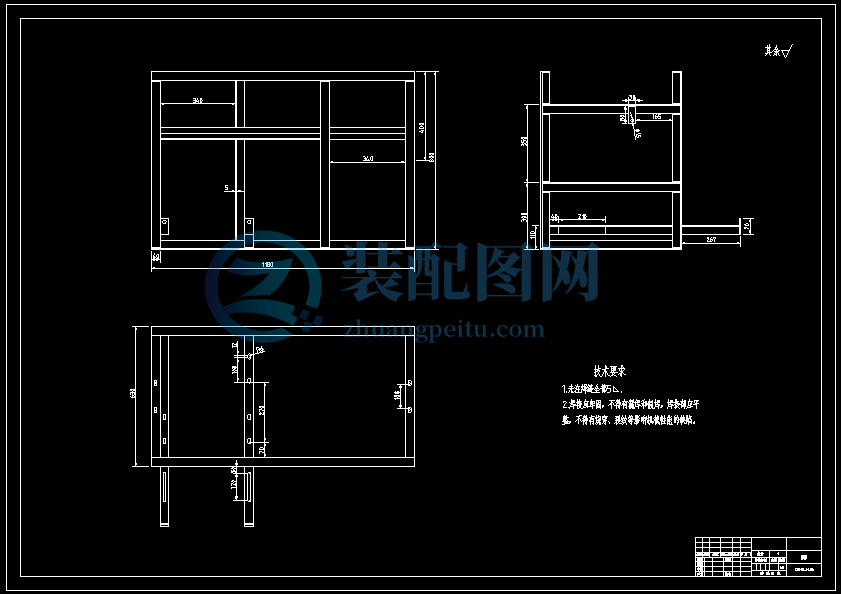
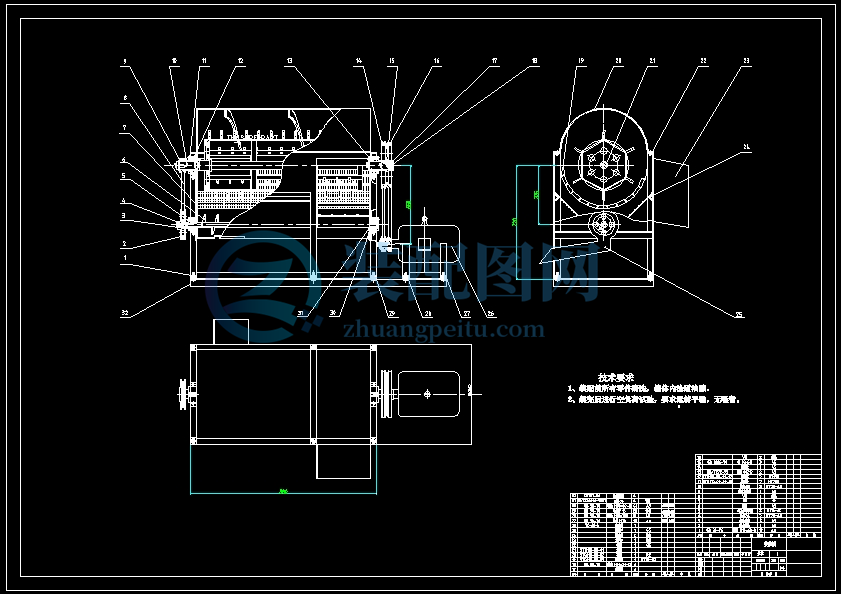
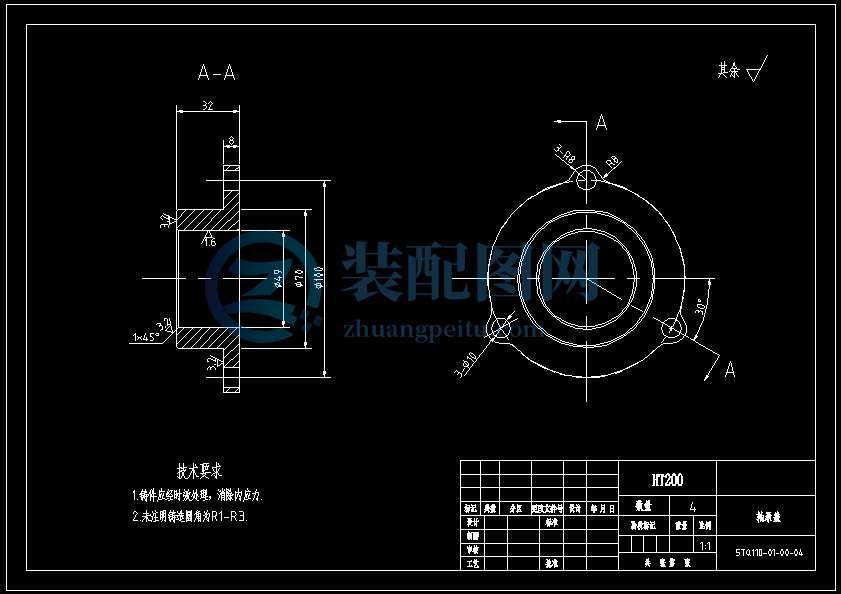
该单株脱粒机主要由脱粒机、传动变速装置、滚筒盖板、
凹板筛、螺旋推进器、电动机、皮带轮及机架等组成(见下图);1具有结构紧凑,脱粒率高等优点。
主要技术参数指标:配用标定功率12.1kw柴油机,标定转数2200r/min,整机净质量155kg。
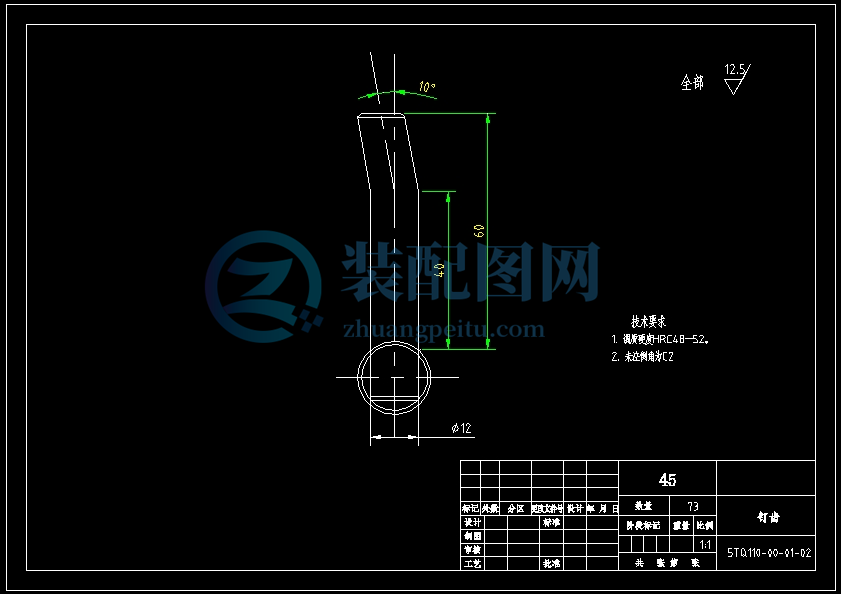
1 机架 2 滑谷板 3 喂入口 4 导向板 5 壳盖 6 钉齿式滚筒 7 排草口 8 凹板筛 9 螺旋推进器 10 物料出料口
11 主动驱动皮带轮 12 联动皮带轮 13 物料出口
2.3 工作原理
工作时,作物由进口均匀进入料机,高速运转钉齿式滚筒把作物送入滚筒内,作物一边做圆周运动,一边轴向运动,而凹板筛对运动物料产生一定阻力,使物料在滚筒的打击下和凹板筛的搓揉下,实现脱离,经过栅格式凹板筛筛孔实现精选。
3 电动机的选择
3.1 电动机类型和结构
电动机类型要由电源、工作条件、载荷特点和转速来选择。
由于本设计没有特殊的要求,本设计电动机均从Y系列中选出。最终本设计选用Y系列三相异步电动机。
3.2 选择电动机的容量
标准电动机容量由额定功率表达, 电机额定功率应略高于工作要求功率。电动机容量由运行时发热条件限定。功率为:
式中: ———电动机输出功率;
———工作所需输入功率;
———总效率;
功率由工作阻力和运动参数得,
或
式中: ———阻力;N
———工作机的线速度;m/s
———工作机的阻力矩;N*m
———工作机的转速;r/min
———工作机的效率;
由于电动机的输出功率已经知道,而且传动效率也在97.5%以上,所以可得工作所需输入功率:
==12.7
3.3 选择电动机的型号
Y系列电动机,通常选用同步转速为1500r/min和1000r/min;综合尺寸、价格以及传动比的特点及大小,我选用1500r/min的电动机比较方便。查阅实用机械手册选用Y2—61—4型号电动机,额定功率13Kw,转速1500r/min,满载时功率因数为0.88。
4 带传动的设计
4.1 确定计算功率Pc
Pc=KaP Ka—工况系数,取Ka=1.1
P---电动机输出功率
则Pc=KaP=1.1×13=14.3KW
4.2 确定V带型号
根据计算功率Pc=14.3KW,电动机转速n1=1500r/min,选用A型带。
4.3 确定传动比i
i==
n1—小带轮转速(r/min) n2—大带轮转速(r/min)
Dp1—小带轮直径(mm) Dp1—小带轮直径(mm)
根据使用要求,滚筒转速n2为1050r/min,电动机转速n1为1500r/min,
则 i==1.43
4.4 计算带轮直径
小带轮的基准直径d1>75mm。初步设定小带轮基准直径为140mm,则大带轮基准直径d2=id1=1.43×140=200,结合本设计要求,取d2为300mm。
4.5 验算带速V
V===11(m/s)
V<25m/s,带速满足要求。
确定中心距a和带的基准长度Ld0
由式0.7×(d1+d2)≤a0≤2×(d1+d2),初定中心距a0=(1.5~2)d2=
1.8×300=540mm,即308≤a0≤880,取a0=550mm。
由传动的几何关系可计算带的基准初值Ld0
Ld0=2×a0+×(d1+d2)+=2×550+×(140+300)+=1802.44mm
查手册,取Ld=1800mm,因此带传动的实际中心距为:
a≈a0+=550+≈550mm
实际中心距的调节范围应控制在a-0.015Ld≤a≤a+0.03Ld之间,安装时应保证
的最小中心距为523mm,最大中心距为604mm。
4.6 校核小带轮的包角α1
P1=180º-×57.3º=180º-×57.3º=163.33º>120º,合格。
4.7 计算所需V带根数Z
查询机械设计手册,得单根V带的基本额定功率P0=2.74KW,额定功率增量△P0=0.28KW,小带轮包角修正系数Kp=0.96,长度修正系数Kl=1.01,
则Z===2.03,取Z=2,选用2根V带。
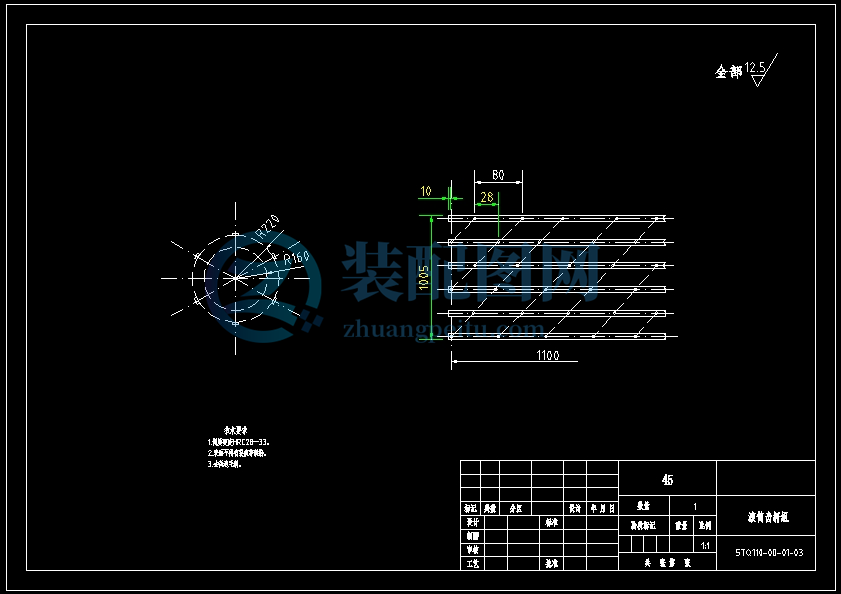
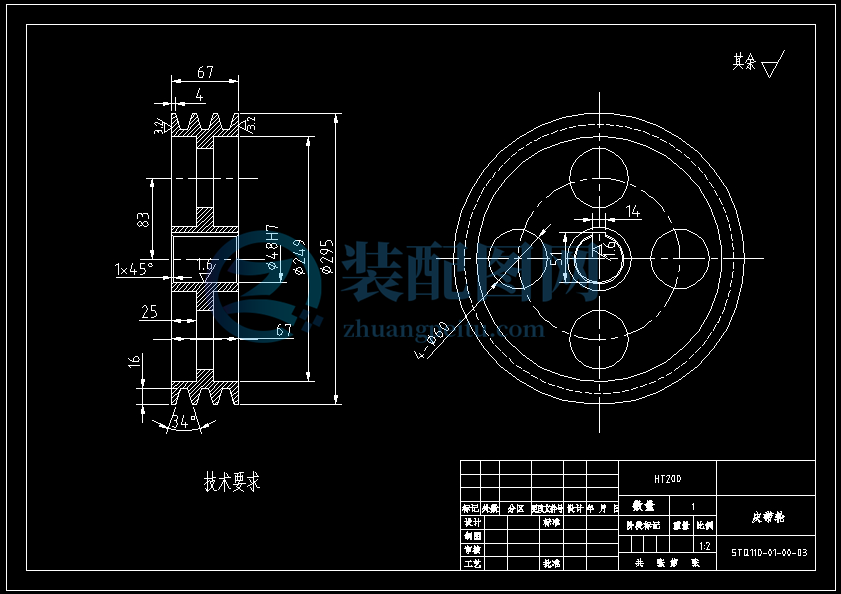
5 螺旋输送器(搅龙)的设计
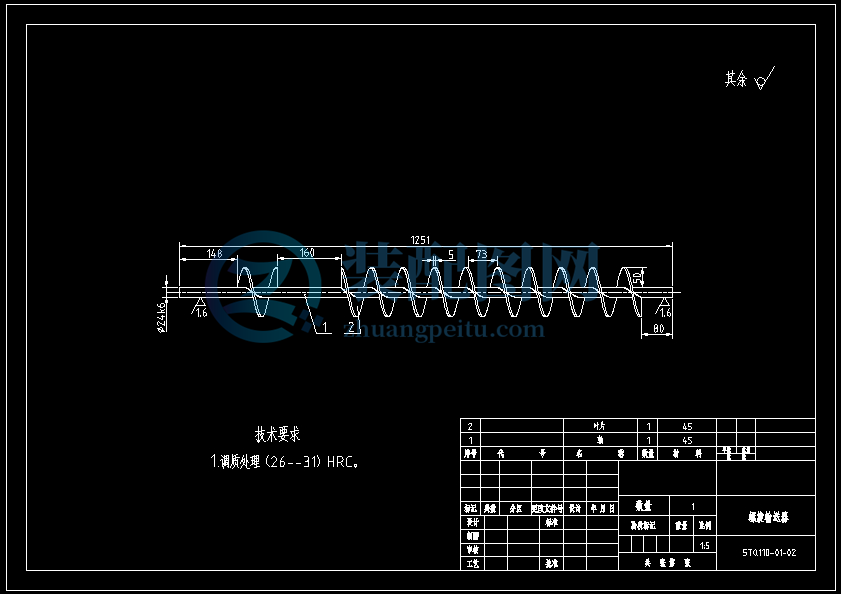
5.1 搅龙的结构型式
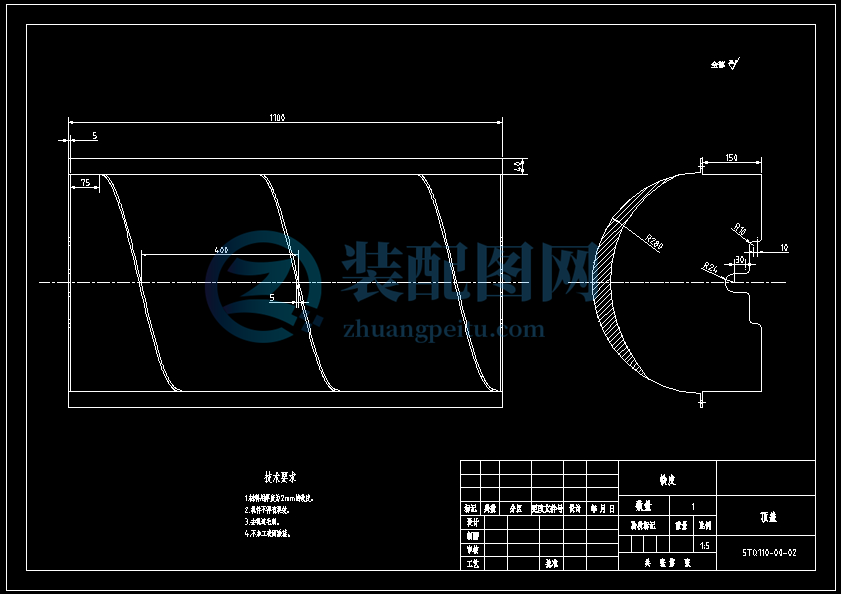
搅龙有整片式,环带式和桨叶式三种,整片式螺旋输送器适用于未脱粒的谷物等,故选择整片式,其结构简单,如图所示:
5.2搅龙叶片的螺旋角
螺旋角越大,生产率越高,但工作费力;螺旋角越小,生产率越低,但工作省力。若角过大,甚至不能工作,为此要寻求出合理的螺旋角。
Vf==Rω
Vz= Vf×cos(+ )= Rω cos(+ )
Vf---输送物的绝对速度 Vn---法向速度,Vn=Rcos Vz---沿Z轴的分速度 ---当摩擦角存在时,输送物质点的运动方向与法线的夹角 ---Vn与Z轴的夹角
搅龙工作时,我们希望输送物有较大的轴向输送速度,以提高输送能力。对Vz求导数,即可求得值。
因为
Vz= Rω cos(+ )
对Vz求导数,并令=0,可得=-。
水稻对铁皮的摩擦角=17º30′。
螺旋角=-时,具有最大的轴向速度。所以螺旋叶片平均半径处的螺旋角=23º30′。
5.3 搅龙的内径D1
对谷粒输送搅龙,搅龙内径就是轴的直径,工作时往往因为其细而长容易出现刚度不够而变形,故设计时常按必须保证搅龙轴有一定的刚度来考虑其内径的大小,常按下面经验式选取。
即
D1=(0.02~0.03)L L---搅龙的长度
由于本设计需要,取L=1258mm,则D1=25mm。
5.4搅龙的外径D2
1.1.1 对谷粒输送搅龙,常取D2=120~200毫米,视机的大小而异,小机的取小些。本设计取D2=124mm。
5.5搅龙的螺距S
搅龙的螺距常按如下经验式选取:
=0.7~1
螺距大,生产率高,工作费力,所以不管是谷粒搅龙或割台搅龙,设计时的比值通常都选用接近下限值。故取S=87mm。
5.6搅龙的转速n
在保证生产率条件下,转速越低越好,因转速越高,消耗功率越多,而且易造成谷粒的破碎和飞散。
对普通谷粒输送搅龙,取n=100~300r/min。由实际情况,取n=200r/min。
5.7计算搅龙带轮直径
小带轮的基准直径Ф1>75mm。初步设定联动皮带轮的基准直径Ф1=90mm
因为 i=== 故Ф2=412,取标准值Ф2=400mm。
取其标准值190mm。
6 机架的设计
6.1 断面形状和尺寸选择
机架的抗拉和抗压刚度,一般仅与其断面面积的大小有关,与断面的形状无关。但在承受弯曲力矩与扭转力矩时,则机架的抗弯刚度与抗扭刚度不仅与其截面面积的大小有关,且与断面形状有很大的关系,即与其断面惯性矩成正比。
1) 圆形空心截面的抗弯刚度及抗扭刚度都比较好。
2)长方形空心断面对提高长边方向的抗弯刚度十分显著,但抗扭强度较差。
3)外形尺寸大而壁薄的断面比外形尺寸小而壁厚的断面的抗弯刚度和抗扭刚度都高,空心结构的刚度比实心结构的刚度大。
4)工字形断面在高度方向上抗弯刚度最大,但抗扭刚度较差。
5)不封闭的断面的抗扭刚度极差。
因此,基于该脱粒机的抗扭刚度不必太高,而要有足够的抗压抗弯刚度,机架断面选择矩形空心截面,可采用角钢。
6.2 结构设计
当脱粒机工作时,机架过高,不易投入物料;机架过低,容易疲劳。一般,H=550~950mm最好。
结合滚筒和电动机的安装,电动机可以通过螺钉固定在平板上,脱粒机的机架设计为如下结构。其结构由热轧不等边角钢焊接而成,具有足够的强度和刚度支撑整个机器的正常工作。
结构如下图所示:
此外,机架底座可以改装成带轮子的,那样移动就更加方便。
7 主轴的设计和校核
7.1 选择轴的材料
轴的材料主要是碳素钢和合金钢,根据传动的功率和一些参数选择材料,最常用材料为45#钢;查《机械设计手册》表11.1查得毛坯直径200毫米,硬度217—255HBS,抗拉强度极限=640Mpa,屈服强度极限=355 Mpa,弯曲疲劳极限=275 Mpa,剪切疲劳极限=155 Mpa。
7.2 确定轴的直径
轴是机械传动的中的重要零件,设计时应满足合理的结构,足够的强度等,轴设计根据轴上零件的定位和固定要求,以及加工和装配要求,合理定出轴的结构外形和全部尺寸过程。
设计轴时必需要先对轴的直径进行必要的估算,由于本实用型的单株脱粒机的主轴主要承受扭矩作用,所以只需按轴所受的转矩来进行计算。
扭矩强度条件为:
= = []
式中: ———轴的扭转切应力,Mpa
T———扭矩,N.mm
n———轴的转速,r/min
P———轴传递功率,Kw
[]———许用扭转切应力,Mpa
—轴的抗扭截面模量,
对实心圆轴,=/16,可得轴的直径:
=
式中C取决于许用扭转切应力[]的系数,当弯矩相对转矩较小时,C取较小值,[]取大值,反之,C取较大值,[]取较小值。
几种轴材料的[]和C值:
轴的材料
1
35
45
40 213
[]
12—20
12—25
20—30
30—40
40—52
C
160—135
148—125
135—118
118—107
107—98
根据轴材料为45#钢,对轴的直径进行估算=44.5毫米,因此所设计的主轴直径取为48毫米。
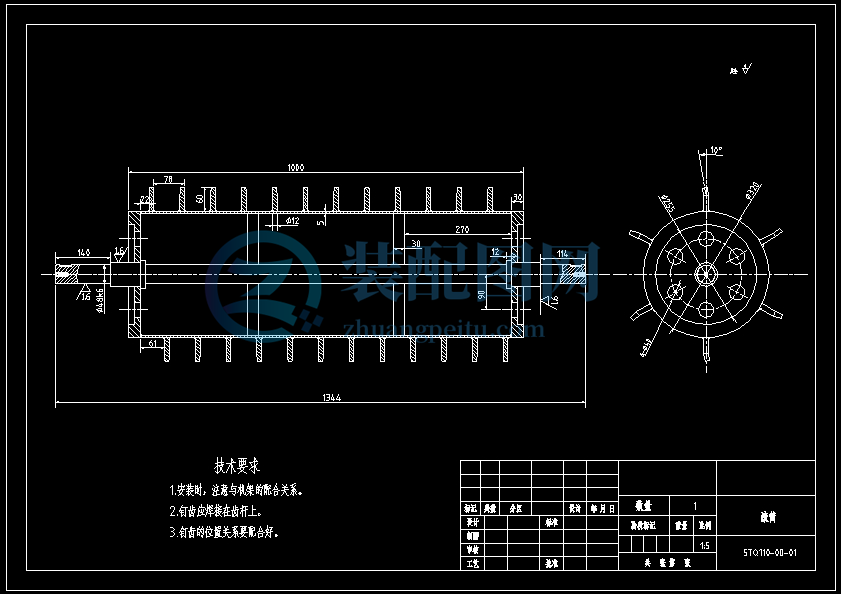
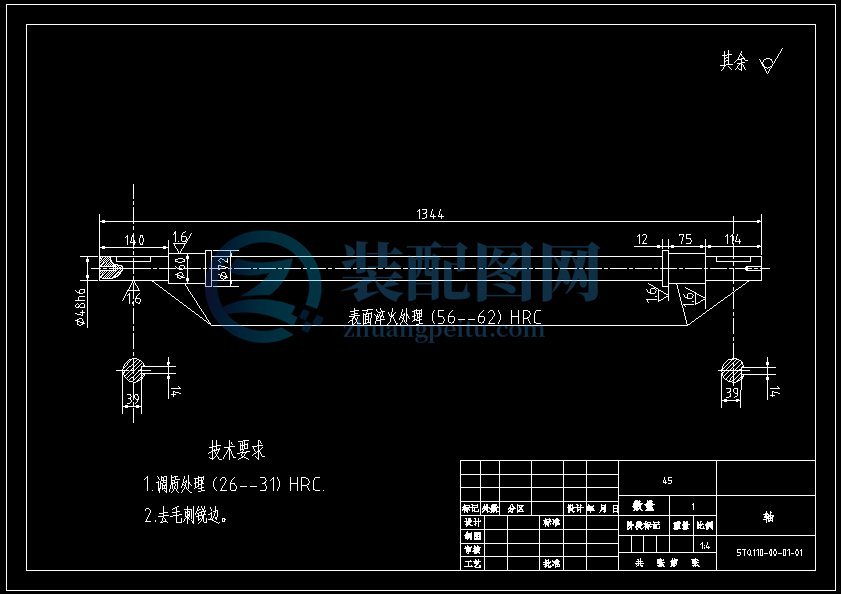
7.3 轴的结构设计
主要承受扭矩的零件,从强度方面考虑,则以圆截面最好,空心矩形的次之,脱粒室的宽度为1000毫米,轴承的宽度为45毫米,轮子边缘到腔壁的间距为140毫米和114毫米,其中主动轮的一端为140毫米,另一端为114毫米。则轴长:L=1000+140+114+2 45=1344毫米。其结构如图所示。
7.4 轴上零件的周向定位
皮带轮的周向定位采用平键连接,由手册查得平键截面b×h=14×9;根据轮毂的宽度选用平键为14×9×70;同时轴肩高度h一般取为:h=(0.07—0.1)d,取为0.08×48=3.84毫米。
7.5 滚筒主轴的强度校核
1. 对轴进行受力分析并简化轴的受力
将滚筒上的受力简化为集中力通过键作用于轴上,轴承对轴的支点反力,轴受到的作用力有:轴承的支点反力、滚筒的作用力、电机的转矩,如下图所示:
2. 计算水平面上的剪切力和弯矩,画出水平弯矩图,并找出危险截面。
剪切力:
==992N =1984N
F点弯矩:
=550mm=5.456Nmm
剪切图及弯矩图如下:
3. 计算垂直面上的剪切力和弯矩,画出水平弯矩图,并找出危险截面。
剪切力:
==1732N =3464N
F点弯矩:
=550mm=9.526Nmm
剪切图及弯矩图如下:
4. 计算转矩
N
对滚筒主轴的强度用第四强度理论校核,则有:
校核结果:
46.38
所以受到最大力的截面安全;轴的强度安全,满足使用要求。
7.6 键连接的强度校核
键连接是把轴和轴上的零件联接起来的形式,键连接具有结构简单,工作可靠等优点。
根据轴径d,查键的标准,得到键的截面尺寸b×h=14×9;根据轮毂的宽度,查键的标准,取L=70;
校核条件:挤压强度
剪切应力
式中: T———传递的扭矩;N.mm
d———轴径;mm
h———键的高度;mm
l———键的工作长度,对A型键l=L-b;mm
———许用挤压应力;M
———键的许用剪应力;M
键的材料:45号钢
校核: = =14.18M
= =4.558M
故满足挤压强度和剪切强度。
8 轴承的选用
轴承的作用是支撑轴及轴上零件,因滚动轴承已标准化,所以我们只需要选型就可以了。
滚动轴承应根据载荷性质、大小、方向等要求来选择。本设计轴只承受径向载荷且承载能力不要求很高,所以我们选择深沟球轴承6000系列。
查袖珍机械设计师手册第二版。
选轴承尺寸如下:d=40,D=62,B2=12,rmin=0.6,极限转速12000(油润滑),轴承代号61908
9 总结
单株脱粒机具有的生产率高,能耗低,各项性能指标优越的特点,目前已运用于我国农业领域。通过此设计,让我对专业知识的运用,有了一定程度上的把握。将理论和实践结合起来,进一步巩固、加深和扩展了所学知识。
通过此次课题设计,学习和掌握了常见机械零件,机械传动装置或简单机械的一般设计方法和原则。培养了分析和解决机械设计问题的能力,为以后进行相关的设计工作打下了基础。
使我在使用掌握计算机绘图、运用并熟悉相关设计资料(包括手册,标准和规范等)以及进行经验估算等方面有了一定程度的提高。
总之,此设计为我学习和工作打下了坚实的基础,为今后从事设计工作奠定了广阔,深厚的基础 。
由于水平有限,在设计中如有不正之处,请指导老师不吝指正。
参考文献
[1]张展,机械设计通用手册,中国劳动出版社,1993.
[2]机械设计,武汉理工大学出版社,2001.
[3]图学基础教程,高等教育出版社,2005.
[4]材料力学,高等教育出版社,2004.
[5]江西省农机研究所,联合收割机的工作原理.
[6]机械工程材料,大连理工大学出版社,2006.
[7]吴宗泽,机械零件设计手册,机械工业出版社,2003.
[8]沈林生,农产品加工机械,机械工业出版社,1988.
[9]张展堂,脱粒机,中国农业机械出版,2000.
[10]李宝筏,农业机械学,中国农业机械出版,2003.
[11] 贾兴梅,李平. 中国农作物产业安全度初步评估[J]. 华南农业大学学报,2012(3): 25-32.
[12] 张海军,韩正晟,王丽维. 单株种子收获机械的研究现状与发展[J]. 湖南农业科学, 2008,139(6): 102-104,139.
[13] 郭佩玉,尚书旗,汪裕安. 普及和提高田间育种机械化水平[A]. 中国农业工程学会第七次会员代表大会论文集[C]. 2004.
[14] 郭佩玉,汪裕安. 努力建成中国的育种机械化体系[J].农业工程学报,1999,15(增刊): 52-55.
[15] 王长春. 田间育种试验机械化的发展[J]. 世界农业,2001(4): 43-44.
[16] 王超,任文涛. 水稻单株脱粒计数仪的研制[J]. 农机化研究,2007(7): 98-100.
[17]王超. 水稻单株脱粒计数仪的研制[D]. 沈阳: 沈阳农业大学,2007,6.
[18]谭建白,王慧如,费殿琪. 农作物脱粒元件的试验研究[J].农机化研究,1993(2): 14-l7.
[19]高连兴,李晓峰,接鑫,等. 农作物机械脱粒损伤特征及损伤率研究[J]. 沈阳农业大学学报,2010,41(1): 55-58.
[20] 牛元民. 浅谈农作物机械收割减少破碎技术[J]. 农作物科技,2008(5): 28.
[21]尹文庆,何扬清. 脱粒装置的结构技术剖析[J]. 农机化研究,1999(4): 42-44.
致 谢
20
Fault diagnostic systems for agricultural machinery
Geert Craessaerts, Josse De Baerdemaeker, Wouter Saeys
Fault detection and diagnosis in process industry have attracted a lot of attention recently. There is an abundance of literature on process fault diagnosis ranging from analytical methods to artificial and statistical methods. From a modelling perspective, the methods can rely on quantitative, semi-quantitative and qualitative models. At the other end of the spectrum, there are historical data-based methods that do not make use of any form of model information but rely only on historical process data. The basic aim of this study is to emphasize the importance of introducing more advanced multivariate fault diagnostic systems on agricultural machinery. Up till now, farmers and contractors still observe the process in order to detect process and sensor failures which can disturb the actions of the controllers and cause severe damage to the machine. In the future, the complete reliance on human operators for the correct functioning of these systems will become too risky, due to the increasing complexity of this type of machinery. A systematic and comparative study of various fault diagnostic methods, from an agricultural machinery perspective, is provided in this study. The different fault diagnostic techniques, investigated in scientific literature, are compared and evaluated on a common set of criteria. Typical requirements of a fault diagnostic system for agricultural machinery are adaptability to process changes, user-friendliness, quick detection and robustness. Based on these findings, a hybrid framework of qualitative model-based fault detection techniques and pattern recognition-based methods, which rely on historical process data, is proposed as the most suitable fault diagnostic technique.
As a first step towards more advanced fault detection and isolation systems, the general applicability of intelligent neural network techniques like supervised self-organizing maps (SOMs) and back-propagation neural networks is illustrated for the detection and isolation of sensor failures on a New Holland CX combine harvester. Pattern recognition techniques, such as neural networks, were found to be very suitable for this kind of application because a lot of historical process data is available since the recent generation of combine harvesters is equipped with a wide range of sensors and actuators, which are continuously monitored. Moreover, these pattern recognition techniques allow quick detection, are easy to use and are able to adapt their structure and/or model parameters based on new measurement data. Since there is room for improvement of these standard techniques, suggestions for future research concerning fault diagnosis on agricultural machinery are given as well.
1. Introduction
The introduction of process control has made a remarkable contribution to the world of agricultural technology. In the past, different processes on agricultural machinery were performed by human operators, but now the larger part is handled in an automatic manner by low and high-level control actions (Coen, Saeys, Missotten, & De Baerdemaeker, 2007; Coen, Vanrenterghem, Saeys, & De Baerdemaeker,2008; Craessaerts, Saeys, Missotten, & De Baerdemaeker, in press). At a supervisory level, human operators still observe the process in order to detect process malfunctions, abnormal events and/or sensor failures which can disturb the actions of the controllers and cause severe damage to the whole process. However, this supervisory task becomes increasingly difficult for agricultural machinery operators due to the ever increasing workload and machine complexity they have to deal with. As a result, human operators often make erroneous decisions concerning the supervisory control of these machines which can have a significant economic, environmental and/or safety impact. Operating on uncertain or missing data may cause improper control actions and consequently the system will not be operating optimally. One of the next challenges for control engineers involved with the automation of agricultural machinery will be the automation of fault detection and diagnosis to further lighten the job of the operator.
In this context, a fault can be defined as a departure from an acceptable range of an observed variable or a calculated parameter associated with a process (Himmelblau, 1978). This defines a fault as a process abnormality or symptom, such as too high a pressure or too high a temperature of a hydrostatic pump. Faults can have different sources and can be classified into three classes of failures: caused by malfunctioning sensors and/or actuators, structural changes in the process or a sudden change of model parameters. The latter one is mainly caused by external disturbances whose dynamics are not taken into account in the process model. In this paper, an overview will be given of the different diagnostic techniques described in the literature for fault detection and diagnosis. Up till now, most of these techniques have been applied in the process industry because of the critical safety norms these processes deal with. It will be shown that fault diagnostic systems have not been given much attention yet in agricultural machinery research. However, these techniques could be of high value at a supervisory control level for agricultural machinery. Based on a formulation of the specific characteristics that a fault diagnostic system for agricultural machinery should include, a suggestion will be made of the most suitable diagnostic methods. Finally, the usefulness of artificial neural networks as a fault diagnostic tool for sensor failure detection will be investigated for an example case. This case study encompasses the detection and isolation of sensor failures on a New Holland CX combine harvester by means of self-organizing maps (SOMs) and back-propagation neural networks.
2. Fault detection and isolation techniques
In the literature, fault diagnosis methods are broadly classified into three categories based on the type and amount of prior knowledge they use. A distinction can be made between quantitative model-based methods, qualitative model-based methods and process history-based methods (Venkatasubramanian, Rengaswamy, Yin, and Kavuri, 2003). The basic a priori knowledge that is needed for fault diagnosis is the set of possible failures and the relationship between the observations (symptoms) and the failures. This a priori domain knowledge may be derived from:
- a fundamental understanding of the process using first principles models: such knowledge is referred to as causal or model-based knowledge,
- historical process data: in this case, the knowledge is referred to as process history-based knowledge. The model-based a priori knowledge can be broadly classified as qualitative or quantitative. The model is usually developed based on some fundamental understanding of the physics of the process. In quantitative models this understanding is expressed in terms of a mathematical functional relationship between the inputs and outputs of the system. In contrast, in qualitative model equations these relationships are expressed in terms of heuristic functions cantered around different units in a process.
An excellent review of the different fault detection and isolation (FDI) techniques discussed in scientific literature is given by Venkatasubramanian, Rengaswamy, and Kavuri (2003); Venkatasubramanian, Rengaswamy, Kavuri, and Yin (2003); Venkatasubramanian, Rengaswamy, Yin, et al. (2003). In this section, these different techniques will be briefly communicated in order to highlight the advantages and shortcomings of the discussed techniques. This critical evaluation will be based on a formulation of the desirable characteristics the ideal FDI system should possess. The conclusions drawn from this review will be of high importance for readers wishing to implement a FDI system for their particular application.
2.1. Desired characteristics of a fault diagnostic system
In Venkatasubramanian, Rengaswamy, Yin, et al. (2003), an overview is given of the characteristics the ideal FDI should possess:
- A quick detection and diagnosis of faults: a trade-off should be made between quick detection of faults and sensitivity to measurement noise. A high sensitivity to noise will lead to frequent false alarms during normal operation.
- Isolation of faults: the fault diagnostic system should be able to make a distinction between different types of failures.
- Robustness: the fault diagnostic system should be robust with respect to measurement noise and model uncertainties.
- Novelty identification: the fault diagnostic system should be able to recognize the occurrence of novel faults and not misclassify these as one of the known malfunctions or as normal operation.
- Classification error estimate: in order to make the system more reliable for the user, a prior estimate of the classification errors that can occur should be provided.
- Adaptability: most processes in the real world are time varying because of changes in environmental conditions and/or product characteristics. The diagnostic system should be adaptable to these changes.
- Explanation facility: besides the ability of the system to identify the source of malfunctioning, the diagnostic system should also provide an explanation of how the fault originated and propagated into the current situation.
- Low modeling requirements: the modeling effort for the development of the diagnostic classifier should be as low as possible.
- Low computational requirements: with an eye on an implementation of the diagnostic classifier on a system with fast dynamics, the implementation algorithm should be of low complexity.
- Multiple fault identification: the fault diagnosis system should be able to identify multiple faults occurring at the same time.
2.2. Quantitative model-based methods
In quantitative model-based FDI methods, one makes use of the inconsistencies, also called the residuals, between the actual and predicted process behavior. As a first step, the residuals between the real system response and the modeled system response are calculated. Any inconsistency, expressed as residuals, can be used for detection and isolation purposes. The residuals should be close to zero when no fault occurs, but show ‘significant’ values when the underlying system changes. In a final step, a decision algorithm will make the appropriate fault diagnosis.
As mentioned above, the generation of the diagnostic residuals requires an explicit mathematical model of the system. Consequently, the complexity and reliability of the resulting FDI system depends on the kind of modeling method and comparison strategy that was used (Venkatasubramanian, Rengaswamy, Yin, et al., 2003). Either first-principles models, black-box or statistical models can be used.
First-principles models are based on a physical understanding of the process and are of high complexity when dealing with supervisory control and diagnosis of a whole plant which very often has non-linear characteristics. As a result, first-principle models are seldom used for fault diagnosis. Most of the FDI methods use discrete black-box and/or statistical plant models such as input–output or state space models and assume linearity of the plant (Venkatasubramanian, Rengaswamy, Yin, et al., 2003).
Process faults usually cause a change in the state variables, a change in the model parameters and/or a change in the output of the process. Based on the process model, one can estimate the non-measurable state variables or model parameters by the observed outputs and inputs using state estimation and parameter estimation methods. Typical state estimation techniques used in fault diagnosis are the Kalman filter and the Luemberger observer (Clark, 1978; Frank, 1986; Patton, Chen, & Nielsen, 1995). These reconstruct the unknown states based on the measurements or subsets of the measurement data. The Luemberger observer is typically used in a deterministic setting while the Kalman filter is mainly used for stochastic processes (Betta and Pietrosanto, 2000). As a consequence, the deviations (residuals) of the model parameters and/or state variables from the normal situation can be used as a fault indicator. Similarly, parity relations (Gertler, 1995; Willsky, 1976) check the consistency of the modeled process output with the real measured process output. Any observed inconsistency would result in a high output residual and indicate the occurrence of a typical fault. Once the residuals are calculated, they have to be evaluated. When designing the decision algorithm, a trade-off should be made between fast and reliable fault detection. In most applications of residual observation, a simple threshold function is used. However, more scientific statistical and/or neural network classifiers are preferred (Koppen-Seliger, Frank, & Wolff, 1995).
When evaluating quantitative model-based fault detection systems, it should be noted that these techniques require a high modeling effort and are generally restricted to linear systems and some specific non-linear systems. For a general non-linear system, linear approximations can be poor and hence the effectiveness of the method can be greatly reduced.
However, thanks to the method of disturbance decoupling, the robustness can be maximized by minimizing the effect of unknown disturbances, like measurement and process noise, and unmodelled process behavior. In this approach, all uncertainties are treated as disturbances and filters are designed to decouple the effects of faults and uncertainties such that these can be differentiated (Frank & Wunnenberg, 1989; Viswanadham & Srichander, 1987).
2.3. Qualitative model-based methods
As noted above, when the a priori domain knowledge is developed from a fundamental understanding of the process by means of physical process knowledge, it is called causal model-based knowledge. When the physics of the process is expressed as mathematical functional relations between inputs, outputs and states of the system a quantitative modeling approach is used as mentioned in the previous section. When the physical relationships are expressed by means of qualitative, non-quantified functions the term qualitative modeling is used. A distinction should be made between the causal models and the abstraction hierarchies (Venkatasubramanian, Rengaswamy, & Kavuri, 2003).
In a first attempt, knowledge-based expert systems, which mimic the fault detection by human experts, were investigated as a tool for fault diagnosis. However, the rule base, which consists of ‘if–then’ rules, grows rapidly with increasing complexity of the system. Another problem of this approach is the lack of insight into the physics of the system which means that it will fail when new conditions are encountered that were not defined in the rule base (Venkatasubramanian, Rengaswamy, & Kavuri, 2003). The need for a reasoning tool which can model the system in a qualitative way and describe it by a causal structure which is not as rigid as a numerical or analytical model has led to the development of different qualitative modeling methods, like digraphs and fault tree structures (Venkatasubramanian, Rengaswamy, & Kavuri, 2003).
A digraph is a graph with directed arcs between the nodes which represents the cause–effect relation of a system. The directed arcs lead from the ‘cause’ nodes to the ‘effect’ nodes. As a result, it is an efficient way of representing the observed symptoms or patterns of a fault in a graphical way. Maurya, Rengeswany, and Venkatasubramanian (2007) proposed a digraph-based fault detection framework to select a possible candidate set of faults based on the incipient response of the process.
Fault trees are mainly used in analyzing the system reliability and safety. The tree has different layers with nodes and at each node logic operations like AND and OR are performed for propagation. Fault trees serve to represent the propagation path of a fault from their origin to their top level of occurrence.
Another way of presenting model-based knowledge is through the development of abstraction hierarchies. These are based on the decomposition of the process system into different subsystems. The main idea is to gain insight in the overall process behavior by inspection of the laws governing the different subsystems. The failure of a higher-level subsystem will be caused by the failure of one or more of the subsystems. The main source of malfunctioning can then be found by making use of a bottom-up description, which describes what various units with certain functions are used for and how these serve the higher-level systems.
When evaluating qualitative model-based fault detection systems, it can be concluded that these techniques are of high value when an abundance of process experience is available which is not numerically detailed. One of the main advantages of qualitative methods based on deep-knowledge is that they provide an explanation of the path of propagation. However, their complexity will increase very rapidly with the complexity of the system and, in comparison with quantitative model-based techniques; they suffer from the resolution problem because no detailed interval or order of magnitude information is available.
2.4. Process history-based methods
In contrast to the model-based fault diagnosis approaches where a process model is needed a priori, only a large amount of historical process data is needed in process history-based fault diagnosis methods. Different kinds of features are then extracted from these historical process data. The extracted features can be of qualitative and/or quantitative nature (Venkatasubramanian, Rengaswamy, Kavuri, et al., 2003). In the former case a distinction can be made between expert systems and trend modeling methods.
An expert system typically consists of a set of heuristic rules derived from a knowledge base. Since considerable process knowledge is often available from experienced engineers and/or operators of the process plant, this can be incorporated. A fuzzy rule base serves as the ideal framework for the incorporation of human knowledge into a fault diagnosis system. Several authors have discussed expert system applications for fault diagnosis of specific systems (Chester, Lamb, & Dhurjati, 1984; Henley, 1984; Rich, Venkatasubramanian, Nasrallah, & Matteo, 1989).
In the case of qualitative trend analysis, the different process signals are monitored and the qualitative analysis of their trends provides valuable information for the identification of underlying abnormalities in the process. These trends can be extracted from a qualitative analysis of the shape of the dynamics of a sensor signal. Venkatasubramanian, Rengaswamy, Kavuri, et al. (2003) state that a suitable classification and analysis of process trends can detect the fault earlier and lead to a quick repair of the faulty sensor.
When extracting quantitative features from a historical data set, the fault diagnosis problem can be solved by pattern recognition techniques. The main goal of pattern recognition is to classify the quantitative features into different predetermined classes based on the interrelationship of these features. The number of classes equals n + 1, with n the number of faults to be isolated. An extra class is needed to cluster the data points which correspond to the normal mode of operation. These pattern recognition techniques can be broadly classified into statistical and non-statistical (neural network) ones.
Traditionally used neural network classifiers are the supervised back-propagation algorithm, self-organizing maps and support vector machines. Some of them will be investigated further in detail in Section 4.2.
When evaluating process his